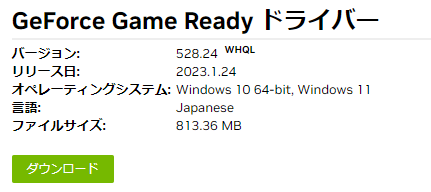
こんにちは。ふらうです。
最近、画像生成にハマってまして、ようやくAUTOMATIC1111の各種機能の使い方や、モデルの違い(checkpoint, Lora, LyCORISとか)が分かってきたところで楽しくなってきました。
なので、今回はおすすめのモデルをいくつか紹介したいと思います。
紹介するモデルは、ほとんど以下のサイトで公開されているものです。
- Hugging Face
- Civitai
今回、初めて画像生成にチャレンジする方やAIを知らない方向けにもわかるよう、解説していきますので上記サイトへの登録方法も含めて解説していきます。
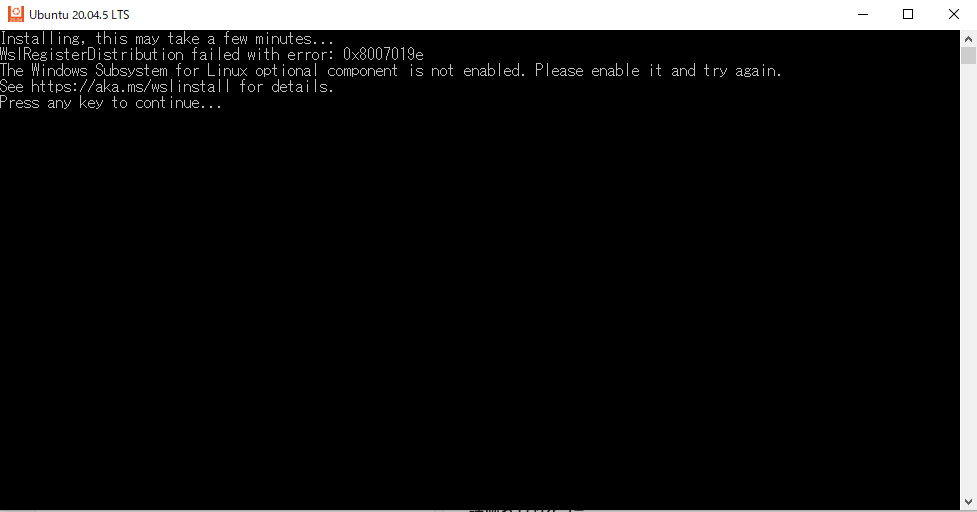
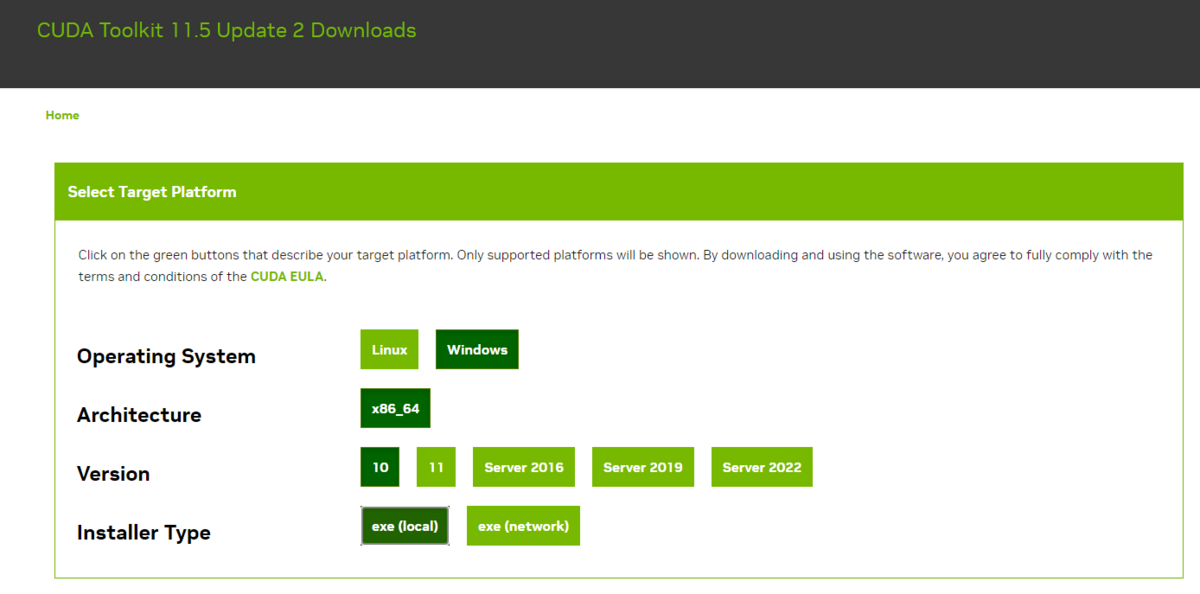
今回はwslのubuntu20.04に導入したstable diffusion webui(AUTOMATIC1111)を使って画像生成する場合を想定しておりますので、この記事で画像生成を知った方や、AUTOMATIC1111を導入していない方は以下の記事で解説してますので、参考にしてください。
もちろんモデルの紹介ですから、それ以外の方法でモデルを使う場合でも大丈夫です。読み込むものは同じですので。
また、「それ以前に環境構築とかわからない!」という方は、以下で環境構築の説明をしてますので参考程度に読んでいただけますと幸いです。
- Hugging Faceとは
- Civitaiとは
- おすすめモデル紹介
- 終わりに
Hugging Faceとは
Hugging Faceは機械学習のツールなどを開発している中で、AIモデルやデータセットなどを公開するためのプラットフォームも提供している企業です。
このHugging Faceのプラットフォームは、AI業界では知らない人はほぼいないプラットフォームで、企業が仕事で参考にするような有名モデルもほとんど公開されている安全なプラットフォームですので、安心してください。
Hugging Faceの登録方法
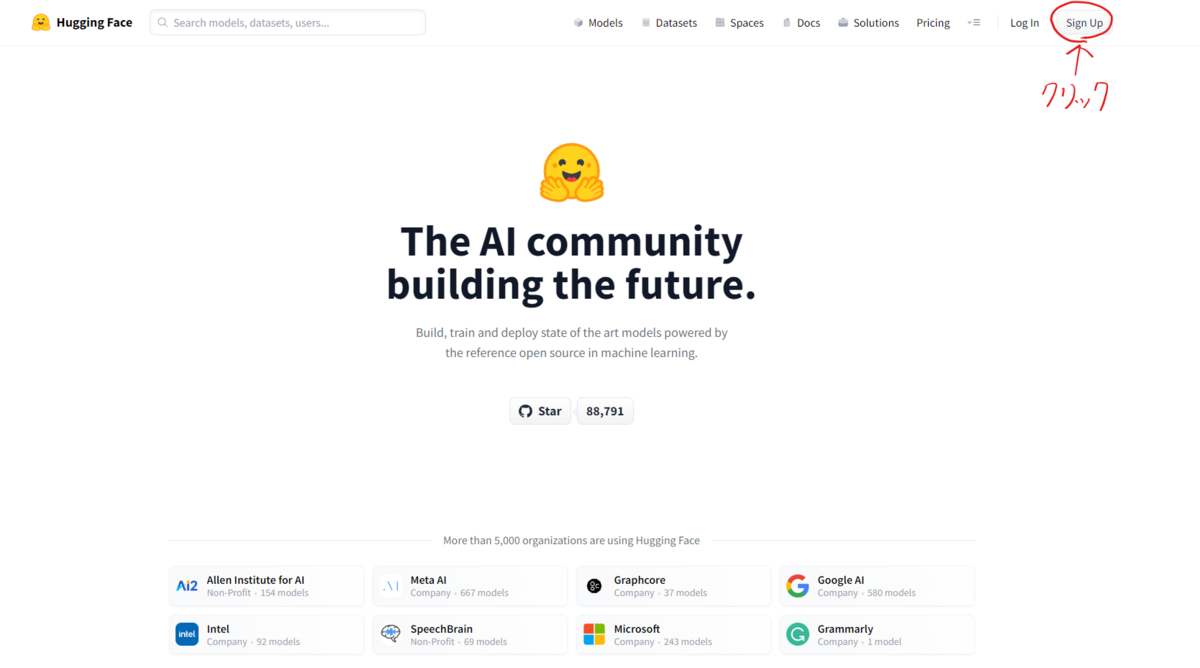
まず、Hugging Faceのサイトへ飛びましょう。
以下のリンクより、プラットフォームへ飛べますので、クリックしてください。
そうしましたら、右上の「Sign Up」ボタンを押してアカウント登録を開始しましょう。
すると以下のような画面になると思うので、Eメールアドレスとパスワードを入力して「Next」を押しましょう。このパスワードは、そのEマールアドレスのパスワードではなく、Hugging Faceのアカウントのパスワードですのでご注意ください。
また、パスワードは、大文字アルファベット・小文字アルファベット・数字の3つを含むパスワードにしなければいけません。あと、12文字以下のパスワードであれば、特殊文字(@など)を含む必要があります。
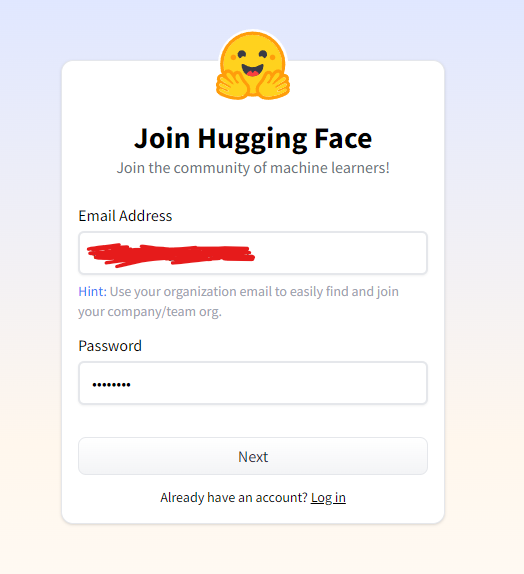
その後、個人情報を入力していきましょう。
usernameとFull nameは必須ですが、それ以外はオプションですので、知らないor持っていない場合は入力しなくて結構です。usernameは重複が禁止ですので、誰かがすでに使っていたusernameだった場合エラーが起きますので入力しなおしてください。
そして、下の「I have read and agree with the Terms of Service and the Code of Conduct」にチェックマークを入れて最下部の「Create Account」を押します。
これで、入力したメールアドレス宛に確認メールが送られますので、そのメールに記載されているリンクをクリックして、先ほどのusernameとパスワードでログインすれば完了です。
Civitaiとは
Civitaiも、Hugging Face同様AIモデルの公開プラットフォームですが、画像生成モデルに特化しているサイトです。
知名度は、Hugging Faceに劣りますがHugging Faceで公開されているモデル +αで数多くのモデルが公開されています。また、公開されるAIモデルにサムネイルが設定されているので、モデル名で探すHugging Faceより探しやすい印象があります。
あと、CivitaiにはNSFW(日本でいう18禁要素)を含むモデルや、版権キャラを生成するモデルが多数公開されていますので、そっち系を生成したい人には必須級のサイトです。
Civitaiの登録方法
まず、サイトに飛びます。以下のリンクより接続してください。
右上のSign Upをクリックしましょう。
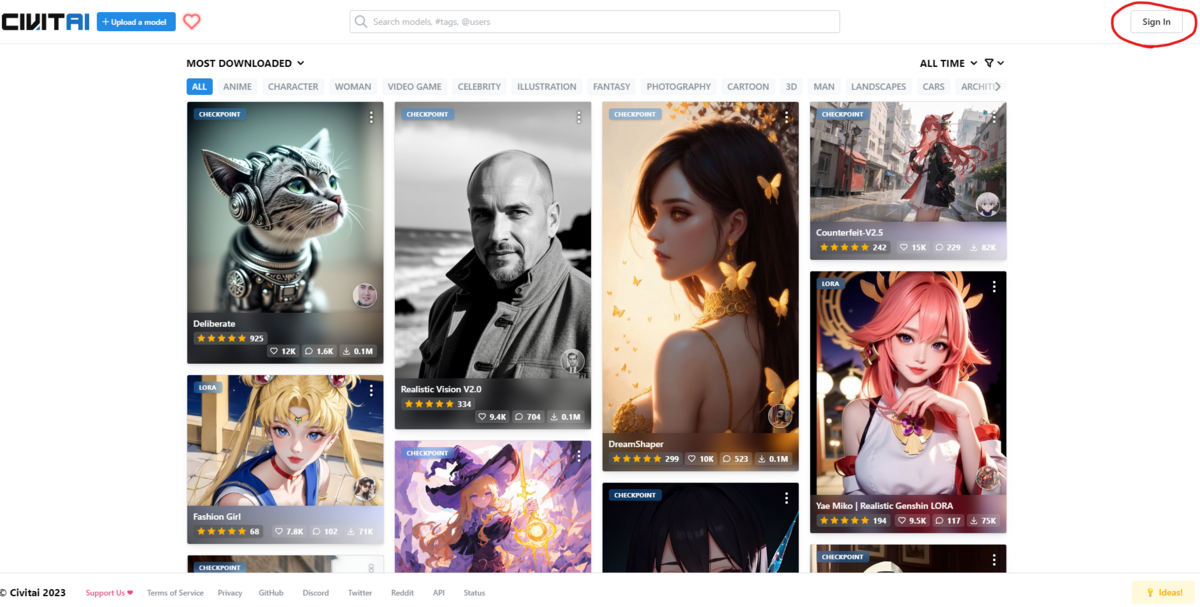
すると、以下のような画面に切り替わります。ここで、「discord」,「Github」,「Google」,「Reddit」のいずれかのアカウントを持っている方は、各リンクからログインしてすぐに使用開始できます。
持っていない方は、下のEmailの欄にメールアドレスを入力すると、そのメールアドレス宛にアカウント登録用のメールが行きますので、説明に従って入力しましょう。
これで完了です。
おすすめモデル紹介
ここでは、主に以下の2種類のモデルを紹介します。
- checkpoint(Stable Diffusionモデル)
- LoRA
checkpoint(Stable Diffusionモデル)
画像生成の大元となるモデルです。
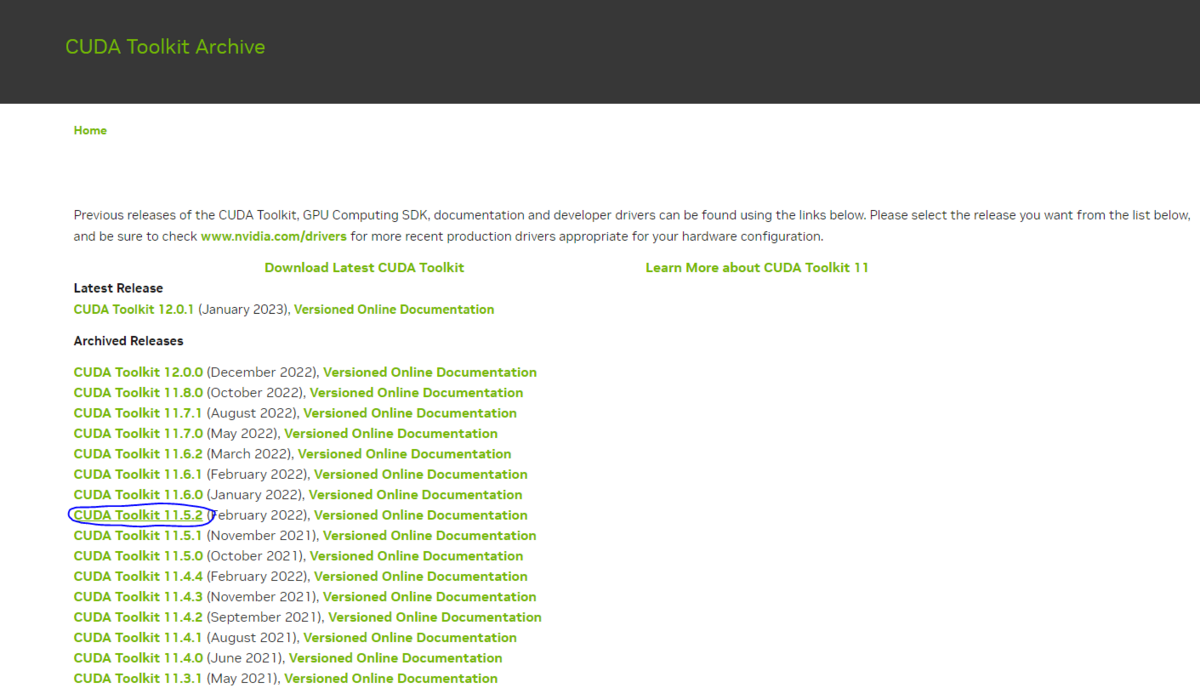
保存場所は、
\\wsl.localhost\Ubuntu-20.04\home\[UNIXユーザーネーム]\stable-diffusion-webui\models\Stable-diffusion
に保存しましょう。
2次元絵生成モデル
Anything v4.5
https://huggingface.co/andite/anything-v4.0/tree/mainhuggingface.co
2次元と2.5次元の絵生成モデルです。
以下のような特徴があります。
- 述べるゲームのスライドのような美しいイラストが生成できる。
- 個人的に、2次元の人物を生成するAIでトップクラスの品質だと思う。
- Anything v3.0の作者とは関係ない人が作ったモデルだが、似ている。
以下のような画像が生成できます。


AbyssOrangeMixシリーズ
2次元絵生成モデルです。
以下のような特徴があります。
- 立体的なアニメ絵から平面的なアニメ絵など様々な用途でモデルが小分けされている。
- NSFWに特化したモデルも多数あるため、本当に幅広く使用できる。
- Anything系と比較できないほど高クオリティの絵が生成できる
以下のような画像が生成できます。
※AOMは(AbyssOrangeMix)の略称です。








中でもおすすめは以下の通りです。
- AOM3A1B
... 後ほど紹介するLoraというものとの相性がよく、幅広い絵を生成できるし、高クオリティ。
- AOM2 hard
... NSFW要素を含む絵を生成したいなら一番クオリティが高いと個人的に思いました。
その他、多数のモデルの詳細は、以下のリンクのmodel cardに記載してありますので確認してください。
https://huggingface.co/WarriorMama777/OrangeMixs
counterfeitシリーズ
2次元絵生成モデルです。
以下のような特徴があります。
- 上のモデルに負けないほど高クオリティ。
- NSFW向けのモデルも用意されている。
- 立体的な絵ではなく、平面的なペンのタッチが分かるような、よりイラスト風味が強い絵を生成する。
- ファンタジー要素が強い絵を生成するのが得意です。
以下のような画像を生成できます。




counterfeit v2.2はNSFWモデルなので、R18な絵を生成するのに特化してます。
Rabbit
2次元絵生成モデルです。
以下のような特徴があります。
- 触ったら逮捕されそうなかわいい人物を生成できます。
- NSFW向けではないので、そっちの趣味の方は向かないかもしれません。(checkpoint mergeすればNSFW向けもいけるかも)
- ふんわりとした涼しげなスタイルの絵を生成します。
- よく動物を手にもっている絵が生成されます。
以下のような画像を生成できます。


BlueMix
2次元絵生成モデルです。
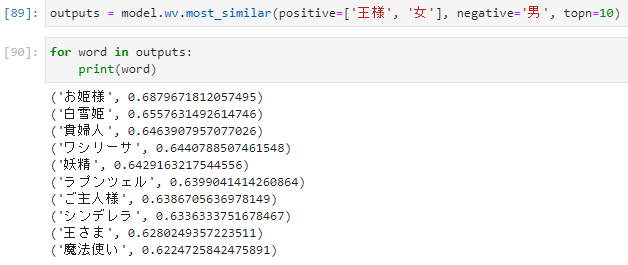
以下のような特徴があります。
- blue archive風のイラストを生成できるモデルです。
- ブルアカ好きならこれ使っとけ
以下のような画像を生成できます。


NineKeyMIX12
2次元絵生成モデルです。
以下のような特徴があります。
- 独特な絵柄でkawaii絵柄が生成できます。
- ninekeyさんが作成しているninekeyモデルシリーズの現時点での最新モデル。
- ちょっとダークな不思議な世界観。
- 3Dレンダリングを行ったことで立体的な絵にも対応
以下のような画像を生成できます。


waifu diffusion v1.5
3次元絵と2次元絵を生成するモデルです。
以下のような特徴があります。
- 2次元と3次元の両方のテイストの絵を生成できる。
- waifuの名の通り基本女の子メイン。
- かなり初期からあるモデルの進化系なので、クオリティが高い。
- 2次元絵に関しては、一昔前のギャルゲとかアニメのような絵のテイストに近い。
以下のような画像を生成できます。


2.5次元絵生成モデル
リアルとアニメの絵柄が融合したような絵を生成するモデルを紹介します。
Perfect World 完美世界
アニメよりのリアルな絵を生成するモデルです。
(追記)2023/05/21 ... 現在v3が新しく登場していて、クオリティが格段に上がりました。以前はloraを使うとlora寄りのテイストによってしまっていたのですが、v3からはテイストを安定して2.5次元の高クオリティの画像が生成でき、loraとの相性も向上したように感じました。
以下のような特徴があります。
- リアル絵の自然な質感とアニメ絵のかわいらしいタッチがいい感じに融合している。
- NSFWコンテンツに柔軟に対応できるよう調節されているためNSFW特化となっている。
以下のような画像を生成できます。


ReV Animated
リアル寄りの絵にアニメのような世界観が合成された絵が生成できます。
ちなみに、このモデルはAnimated版ですが、ほかにもいろいろ作られている方ですので興味がある方は探してみてください。
以下のような特徴があります。
- CGで作成される絵に似ている。
- ファンタジーやアニメよりの世界観に特化。
以下のような画像を生成できます。


3次元絵生成モデル
ChilloutMix
リアルな絵を生成するモデルでの大手です。多数のユーザーが使用している故に多くのサンプルイラストが生成されていて、クオリティもかなり高いです。
以下のような特徴があります。
- 現実の人間と相変わらないリアルな絵を生成可能。
- SFW・NSFW両方に対応
以下のような画像を生成できます。


DreamShaper
3次元絵生成モデルです。
以下のような特徴があります。
- 人気モデルなのでサンプル画像が多数あります。
- 背景や風景の描写が超高クオリティ。
以下のような画像を生成できます。


LoRA
LoRAは簡単に言えば追加学習のデータです。
既存のStable Diffusionモデルをさらに何かに特化させたいときに指定すると、より自分の好みに合った画像が生成できるといったものです。
LoRAは非常に強力ですので、絵のテイストも変化させてしまう可能性があるので注意してください。
保存場所は、
\\wsl.localhost\Ubuntu-20.04\home\[UNIXユーザーネーム]\stable-diffusion-webui\models\Lora
に保存しましょう。
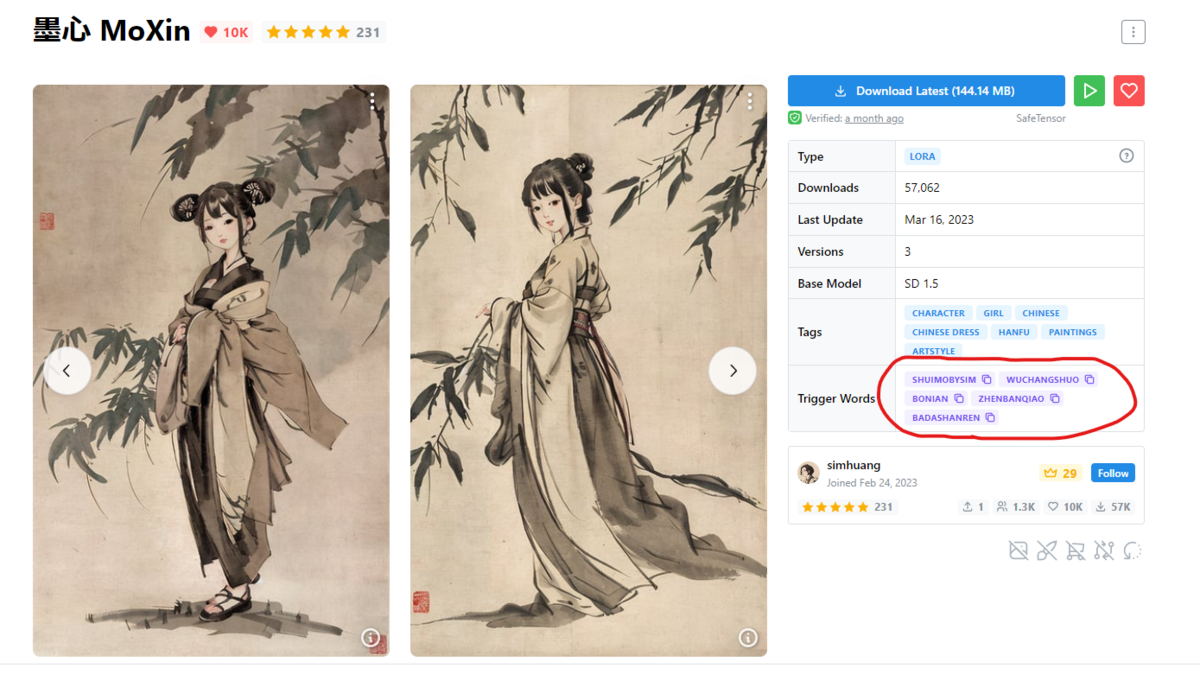
使用方法としては、trigger wordをプロンプトに書く方法が一般的です。例えば、1つ目に紹介する「墨心 MoXin」では、プロンプト内に、LoRAを使うためのプロンプトの「
分からない方用に補足説明をします。
AUTOMATIC1111の画面左にある花札のようなマークをクリックすると、次の画像のように新たなオプションが出てきますので、「Lora」タブに移動して目当てのLoRAを選択しましょう。
もしすでにたくさん入れてあって探すのが面倒という方は、入力欄に目当てのLoRAの名前の一部を入れると絞れるので活用しましょう。

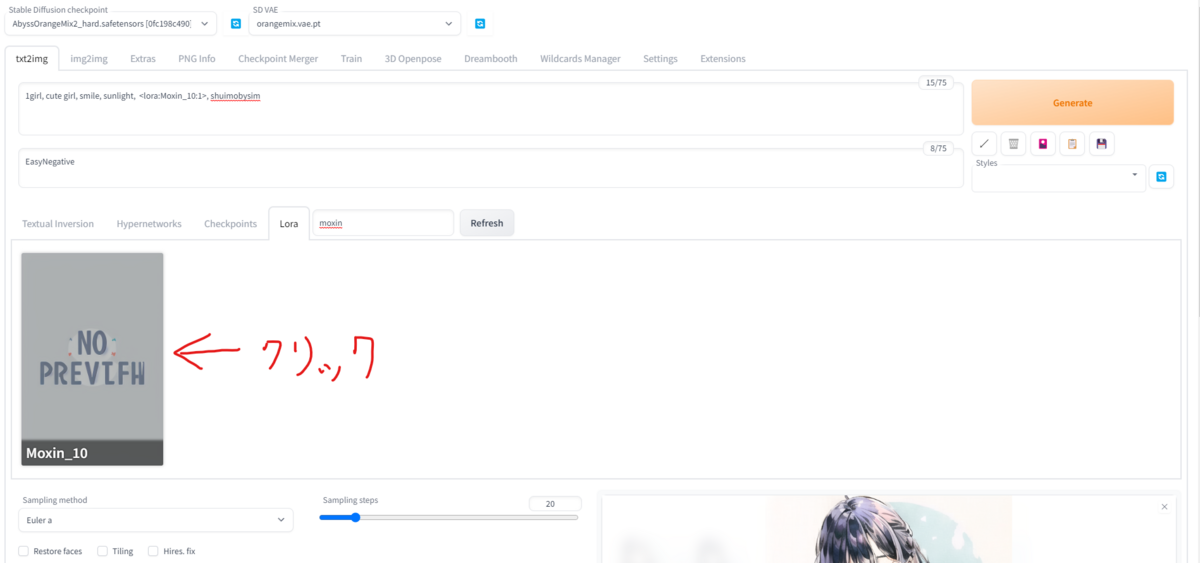
この場合、Moxin_10をクリックすると、自動的にプロンプトにloraのtrigger wordが追加されます。
また、さらに特徴を絞るために用意されているtrigger wordはCivitaiのページに記載がありますので、その英語をそのままコピーしてくればokです。
以下の画像では「墨心 MoXin」のtrigger wordが記載されている場所の例ですが、その中に今回使う「shuimobysim」があると思います。ここに何も書かれてなくても、説明欄に書かれている場合がありますのでいろいろ見てみるといいでしょう。
また、版権キャラもほとんどがLoRAで指定しての出力になると思います。したがって、LoRAは基本的に絵のテイストの指定か、絵の中の人物を変化させること中心に利用されることとなります。
※版権キャラを生成する場合は、規約の利用範囲内で行うようにしましょう。
墨心 MoXin
水墨画のような、美しい絵に変化させます。
CivitaiのLoRAモデルの中でも人気のあるもので、筆者も利用させていただいております。
以下のような画像を生成できます。


Gacha splash LORA
ガチャの登場演出のような背景にすることができます。
これもまた人気のLoRAで、ガチャSSRの登場シーンのような画像を生成して個人的に楽しんでます。また、これと原神のLoRAなどと組み合わせれば、派手で美しいオリジナルのガチャ排出シーンを作れて楽しいです。
以下のような画像を生成できます。


Anime Lineart
線画スタイルの絵に変更することができます。
色塗り前の線画っぽい絵を生成できます。こういった絵も趣があっていいと思いますし、色塗り練習にももってこいですね!
以下のような画像を生成できます。


Button
ボタンのイラストを生成するモデルです。生成される絵はボタンの左半分だけですので、生成された後は画像編集ソフトなどで左右反転コピーしたものを結合して使うといいですね。
以下のような特徴があります。
- 高クオリティなボタンのイラストを生成できる。
- おすすめサイズは512*768で生成。
- 細かくプロンプトの指定ができる。
- 原神などの鮮やかな感じのボタンに似ている。
以下のような画像を生成できます。


Minimalist Anime Style
落ち着いた雰囲気のアイコンを生成できるようになるのでかなりおすすめです。


Anime Tarot Card Art Style LoRA
タロットカード風の背景の画像を生成できます。
タロットカードいいですねぇ...。印刷してカードにしたら個人的に現実で楽しめますね!
以下のような画像が生成できます。


ウマ娘 LoRA
モデルというより、ユーザーの紹介です。
ウマ娘の出力に特化したLoRAを数多く作っておられます。たいていのキャラは網羅しているので自分好みの絵が作れそうですね。ただしR18作品の販売、公開は公式様によって禁止されていますので、どうしてもしたい方は、必ず個人での利用にとどめるようにしましょう!
正直かなりクオリティ高いです....(脱帽)。
以下のような画像が生成できます。






めっちゃクオリティ高いですね...。LoRA恐るべし...。
LyCORIS について
たまにLoRAを探していると、LoRAではなくLyCORISのタグが付いたものがあります。これもLoRAと同様、モデルをダウンロードしてtrigger wordをプロンプトに入れれば動くのですが、ただでは機能しません。
以下に、動くようにする手順を書きますので、LyCORISを使いたい方は参考にしてください。
- まず、AUTOMATIC1111を起動する。
- 「Extensions」タブの「Install from URL」タブを開き、「URL for extension's git repository」の入力欄に「https://github.com/KohakuBlueleaf/a1111-sd-webui-locon」と入力し、Installを押します。
- 「Installed」タブに移動し、「Apply and restart UI」をクリックしてUIを再起動します。
- 「Extensions」タブの「Installed」タブの拡張機能リストに「a1111-sd-webui-locon」が追加されていればok
あとは、LyCORISのファイルをLoRAと同じフォルダに保存すれば完了です。
そのあとは、LoRAと同じように使えるようになります!
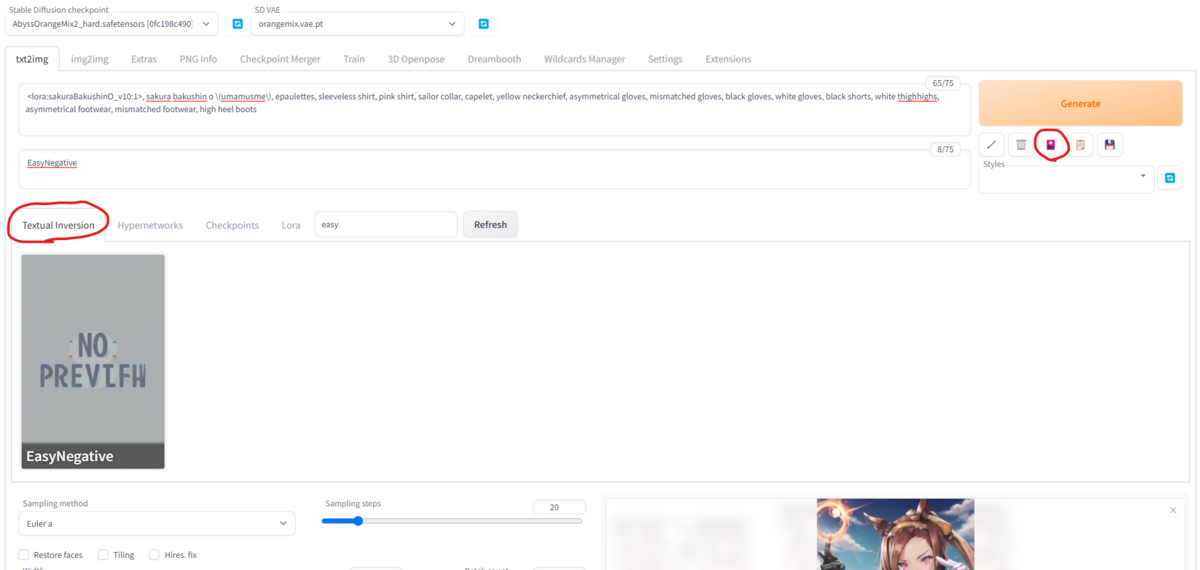
TEXTUAL INVERSION について
TEXTUAL INVERSIONタグが付いているものは、ほかのファイルとは保存場所が違うので注意が必要です。以下のようなフォルダに保存しましょう。
\\wsl.localhost\Ubuntu-20.04\home\[UNIXユーザーネーム]\stable-diffusion-webui\embeddings
すると、AUTOMATIC1111の「Textual Inversion」タブに項目が現れ、使用可能になります。その項目をクリックすれば、LoRAなどと同じようにプロンプトに自動でtrigger wordが追加されます。
ちなみに、「Textual Inversion」タブは、LoRAを選択するときと同様、花札マークをクリックすると現れます。
Negative promptについて
いい絵を生成するには、ネガティブプロンプトも考える必要があります。
ですがここで朗報です。
単語一つで、主要なネガティブプロンプトを追加してくれるものがあるんです。
これも、Textual Inversionの機能を使うものなので、ファイルをダウンロードして、Textual Inversionと同じembeddingsフォルダに保存すれば使用可能になります。
私が一つ前でTextual Inversionの説明しているときに貼ったAUTOMATIC1111の画像のネガティブプロンプト欄に「EasyNegative」と一言書いてあるのが分かるかと思います。
この単語一つで、長々と「lowres, *1, *2, text, missing finger, extra digits, fewer digits ...」と入力しなくてもいい画像が生成されるようになります。
私自身この機能は必須級だと思うので、おまけでおすすめをいくつか紹介します。
EasyNegative
私が一番愛用しているもので、おすすめモデル欄でも紹介した「counterfeitシリーズ」の作者が開発したものです。
アリとナシの違いをいかに示してみます。




まったく同じモデルとプロンプトで生成しているにもかかわらず、ネガティブプロンプトの違いでここまで変わります。すごいですね...。
Deep Negative
こちらもかなり人気のものです。人の手の感じや体の欠陥・不快な色・空間構造などを配慮して作られたものです。
また、こちらは、Stable Diffusion2.x系をもとにトレーニングされているので、Stable Diffusion2.xをもとに作られたモデルのネガティブプロンプトに設定すると相性がいいです。
アリにした場合の生成画像を以下に示します。
比較対象は上で生成された「EasyNegativeなし」の画像を参考にしてください。


終わりに
今回は、Stable Diffusionの様々なモデルを紹介しました。
日々、新しいモデルやembeddingが生まれているので、紹介しきれなかった部分もあります。
私個人の意見としては、LoRAやLyCORISに関してはCivitaiで探したほうが探しやすいですし、多くのモデルがあるので選びやすいと感じました。
ここまで読んでくださりありがとうございます。
では、よいAIライフを!