こんにちは、ふらうです。
今回は、Word2Vecの学習を実行していきます。
学習の手順としては以下の通りです。
- 学習データの準備
この段階で進めていきます。なお、出来上がった学習済みモデルはGitHubにて公開するので、ご自由にご利用ください。
公開しました!以下のリンクよりgithubへ飛べます。
https://github.com/Frq09/w2v.git
学習データの準備
今回学習に使うデータは2023年3月1日時点の日本語wikipediaコーパスです。
日本語wikipediaコーパスのダウンロード
まず、日本語wikipediaコーパスをダウンロードしましょう。
以下のコマンド、もしくはリンク先でダウンロードしてください。
- コマンド
curl https://dumps.wikimedia.org/jawiki/latest/jawiki-latest-pages-articles.xml.bz2 -o jawiki-latest-pages-articles.xml.bz2
- リンク先のページから
https://dumps.wikimedia.org/jawiki/latest/
リンク先のページに飛んだら、”jawiki-latest-pages-articles.xml.bz2”というファイルを探してダウンロードしましょう。
これが日本語wikipediaの全文のデータです。
約3GBあるので気長に待ちながらダウンロードしましょう。
フォルダの解凍および前処理
保存したwikiコーパスを解凍して前処理を施していきます。
まず、解凍および簡単な前処理を実行する、WikiExtractorをインストールしてwikiコーパスに適用します。
WikiExtractorは、bz2フォルダを解凍すると同時にwikiコーパスに含まれている余計なデータを除外して分割保存してくれます。
WikiExtractorは以下のいずれかのコマンドでインストールしてください。
- pipからインストール
pip install wikiextractor
- gitから直接インストール
git clone https://github.com/attardi/wikiextractor.git
pipからインストールした場合、pipのバージョンが古い場合は古いwikiextractorがインストールされてエラーが起こる可能性があります。逆にgitから直接インストールした場合は、最新版が必ず手に入りますので安心です。
インストールが完了したら、wikiコーパスに対して実行し、解凍、前処理を行います。
python -m wikiextractor.WikiExtractor jawiki-latest-pages-articles.xml.bz2
そうすると、textというディレクトリが生成され、AA,AB,AC...BKまでの名前のサブディレクトリが生成される。そしてそのサブディレクトリの配下にwiki_00~wiki99までの100ファイルが生成される。これが、wikipediaの情報が集約されたプレーンテキストファイルです。
中身はこのようになってます。

次に、残っている不必要な情報および空行を削除する。
まず、分割されたすべてのファイルを1つのファイルに統合します。
- linux環境であれば以下のコマンド
find text/ | grep wiki | awk '{system("cat "$0" >> wiki.txt")}'
- windows環境であれば、powershellにて以下のコマンドを実行する。
Get-ChildItem text/ -Recurse | Where-Object { $_.Name -like "*wiki*" } | ForEach-Object { Get-Content $_.FullName >> wiki.txt }Pythonで実行したい人は以下のプログラム(wiki-merge.py)
import os # フォルダ内のファイルを再帰的に検索 for root, dirs, files in os.walk("text/"): for file in files: # ファイル名に「wiki」という文字列が含まれるか確認 if "wiki" in file: # ファイルを開いて、内容を`wiki.txt`に追記 with open(os.path.join(root, file), "r", encoding='utf-8') as f: with open("wiki.txt", "a", encoding='utf-8') as wf: wf.write(f.read())
これで統合が完了したので、不必要な情報と空行を削除します。
- 不必要な情報の削除(wiki-delete-tags.py)
import re # 空のHTMLタグを削除する with open('wiki.txt', 'r+', encoding='utf-8') as file: content = file.read() new_content = re.sub(r'^<[^>]*>$', '', content, flags=re.MULTILINE) file.seek(0) file.write(new_content) file.truncate()
- 空行の削除(wiki-delete-tags.py)
import re with open('wiki.txt', 'r+', encoding='utf-8') as file: content = file.read() new_content = re.sub(r'^\n', '', content, flags=re.MULTILINE) file.seek(0) file.write(new_content) file.truncate()
これらを実行すると、不必要だったdocタグや空行が削除される。
以下のコマンドでデータ数を確認してみる
wc -ml wiki.txt
結果は、1317104729文字で、16329952行のデータであった。
分かち書きする
Word2Vecの学習に必要なデータ形式は、分かち書きされた文章です。
Word2Vecは、文章に含まれる単語を前後から予測するか、前後を予測するかで単語ベクトルを算出しています。
なので、学習で使われるデータは、文章ごとに区切られた分かち書きされている文章である必要があります。英語であれば「This is a dog.」などと単語ごとにもとから区切られていますが、日本語の文章では「これは犬です。」と区切られていないので、自分で分かち書きし、「これ は 犬 です 。」という風に加工する必要があります。
一般的な方法では、文章ごと改行した分かち書きデータを、word2vec.LineSentence関数で学習データにするのですが、今回はこの関数を使わずに、分かち書きから入力形式を合わせるところまでを手動で行います。
- 必要ライブラリ
from gensim.models import word2vec import MeCab import re import logging from tqdm import tqdm from multiprocessing import Pool
word2vec ... word2vecに関するライブラリ
MeCab ... 分かち書きを行うためのライブラリ
re ... 句点などで分割するために使用
logging ... モデルの学習中など、進行状況を可視化させるために使用
tqdm ... 処理の進行状況を可視化するためのライブラリ
multiprocessing ... 大規模な処理を複数のプロセスで並列処理し、高速化するために使用
with open("wiki.txt", "r", encoding='utf-8') as f: text = f.read()
wiki.txtから文字列として変数textに格納していきます。
- 改行か句点で分割
sentences = [] for s in tqdm(re.split("[\n。]", text)): s = s.strip() if s: sentences.append(s + "。")
re.split("[\n。] で改行文字および句点で分割を行い、変数sentencesにlist型で格納していきます。
- 空の要素の排除
sentences = list(filter(None, sentences)) print(len(sentences))
上のやり方ではlistに空の要素ができてしまうので、filter関数で空の要素を排除します。
- 分かち書きを行う関数を定義
def tokenize(text): tagger = MeCab.Tagger('-Owakati -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd') return tagger.parse(text).strip().split()
分かち書きを行うのでtaggerの引数には"-Owakati"を指定し、辞書は"mecab-ipadic-neologd"を指定する。
- list全体に上記の関数を実行する関数を定義
def tokenize_list(text_list): with Pool() as pool: results = list(tqdm(pool.imap(tokenize, text_list), total=len(text_list))) return results
この処理がかなり長いので、"Pool"を使用し複数のプロセスで並行処理を行うことで高速化をおこないます。
そして"imap"メソッドを使用してイテレータを返すジェネレータを作成、そのイテレータから結果を収集し、resultsとして返します。
- データ加工
w2v_train_data = tokenize_list(sentences)
変数sentencesに対して分かち書きを実行します。
この処理はマルチプロセスで高速化しても私の環境では13時間~14時間ほどかかりました。
これでデータ加工の段階は完了です。
もしエラーが不安でword2vec用の分かち書きデータを保存しておきたい場合は以下のプログラムを使ってください。
def save_words_to_file(word_list, filename): with open(filename, "w", encoding='utf-8') as file: for word in tqdm(word_list): file.write(" ".join(word) + "\n")
save_words_to_file(w2v_train_data, 'wiki_wakati.txt')
このプログラムでは、分かち書きされたリストを一行一文ずつテキストファイルに書き出していくプログラムになります。
次にこのデータを使いたいときは、word2vecのLineSentenceの引数にこのテキストファイルを指定してあげることで、今と同じようなデータになります。
- 読み込み方
w2v_train_data = Word2Vec.LineSentence(wiki_wakati.txt)
学習
それではすべての準備が整ったので学習を実行していきましょう。
進捗の表示
その前に、学習の進捗が表示されないのは不安なので、loggingを使って進捗表示させるようにしましょう。必要ないと思う方はつけなくても、何ら学習に変化はないので大丈夫なのですが、進捗スピードやメッセージなどが見えた方が分かりやすいと思うので、進捗表示させておくことを推奨します。
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
学習の実行
以下のプログラムで簡単に学習が開始できます。
model = Word2Vec(w2v_train_data, size=200, window=5, sample=1e-3, negative=5, hs=0)
オプションの詳細は以下のサイトの方がわかりやすく説明してくださっているので、ご自分でオプションを変えたいという方は参考にしてみて下さい。
qiita.com
また、今回の学習オプションは、東北大学のWord2Vecモデルの学習のオプションを参考にしています。
モデルの保存
学習が終わり次第、以下のコードでモデルを保存しましょう。
model.save("word2vec.model")
実験
今回作ったモデルでいろいろ実験してみましょう。
類似単語の検索
- 「ドラゴンボール」の類似単語
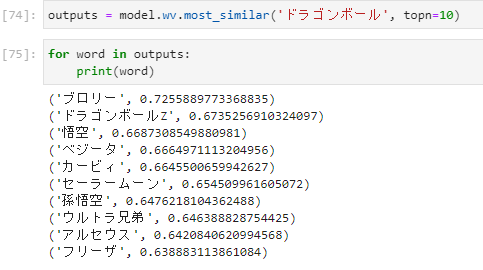
- 「ガンダム」の類似単語
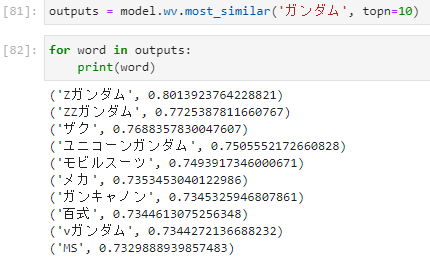
- 「ウマ娘」の類似単語
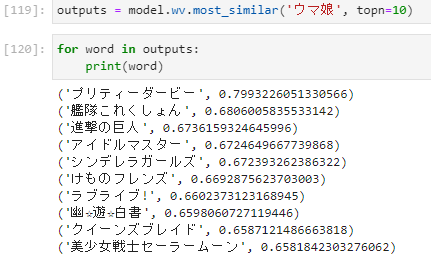
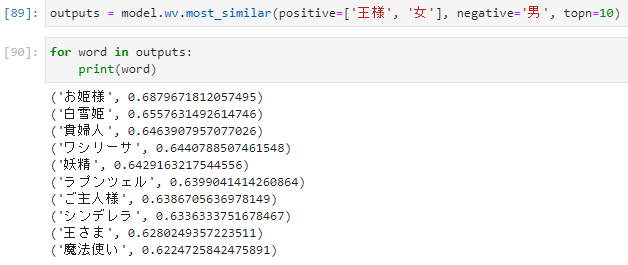
単語の足し引き
「王様」+「女」-「男」
まとめ
今回はWord2Vecの学習と実験を行いました。
このモデルとコード類は、私のgithubで公開予定公開済みですのでどうぞご自由に使ってください。
では、また次回の記事もよろしくお願いします。
参考文献
- word2vec公式Reference