アニメの世界を合成!?自分のPCでAI画像生成を行うまでの方法と、DreamBoothの使い方をできるだけ詳しく解説!!自分で体験する画像生成の進化
こんにちは。ふらうです。
皆さん。「あのキャラクターがあの仕事をしていたらどうなるんだろう...」、「あのキャラクターがこんなことしていたらどういう風になるんだろう...」、「あのキャラとあのキャラのカップリングを見てみたい!」と考えたことはありませんか?
...私はあります。
今回は、それを可能にする、DreamBoothについて書いていきます。
よくpixivやtwitterでアニメやゲームの版権キャラのAI絵を生成して公開されている方がおられますが、そういう絵をDreamBoothを使って生成することができるらしいのです。
そこでDreamboothについて気になったので調べてみようと思いました。
ちなみに、無許可で絵師さんの絵を学習材料にして、同じテイストの絵を販売したり公開したりすることは、あまりよくないです。AIが生成する絵の著作権は基本的には生成者が有することになるのですが、学習に入れる絵に著作権がある場合ちょっと話が変わってきます。
私は専門家でもなければ法律に詳しいわけでもないので詳しいことは何も言えないのですが、自分が何日もかけて一生懸命描いた絵を、勝手に学習材料にされて似た絵を大量生成し、その絵に人気が行くとなんだか悲しい気持ちになります。なんだか自分の技術をコピーされて転売されているようで...。
もし好きな絵師さんの絵を材料に、似たテイストの新たな絵をAIに描かせたいなら個人の利用範囲にとどめておくことをお勧めします。
今回の実行環境は、Windows版Anacondaではなく、WSL2のubuntu20.04です。ご注意ください。
- DreamBoothとは
- 画像生成モデルができるまで
- 画像生成モデルの欠点
- DreamBoothで欠点解消
- DreamBoothの画像生成の変化の一例
- DreamBoothを使えるようにする
- 終わりに
DreamBoothとは
DreamBoothは、Googleの研究チームとボストン大学の方々が確立した技術で、2022年8月に論文を公開し反響を呼びました。
この技術というのは、既に学習してある画像生成モデルに対して、新たな数枚の画像を出力領域に埋め込み、その数枚の画像と似たテイストの絵を生成するようになるというものです。ファインチューニングというやつですね。これによって、様々なシーンで文脈にあった画像を新たに生成できるようになります。
もとになった論文を以下に貼っておきますので、元論文を読みたい方はURLから飛んでください。
画像生成モデルができるまで
近年発表された画像生成モデルは、タグと画像を結び付けて学習しています。例えば"犬が走っている画像"には、タグとして「"dog", "dog run", "run" ...」、猫が寝ている画像には「"cat", "sleeping cat", "sleeping" ...」などタグが付いています。
こうしたソースで学習されたモデルで画像生成するとして、プロンプトに「cat run」と入力します。すると、猫の特徴をとらえたデータに犬が走っているデータが合成されて猫が走っているような画像が生成されます。
画像生成モデルの欠点
こんな画像生成モデルにも欠点があります。それは、学習データにない単語を入力されても、AIが理解出来ないのでめちゃくちゃであるか、本質とはかけ離れた画像を生成します。
例えば上記の犬と猫のデータで学習したモデルに、「sleeping rabbit」と入力しても、おそらくウサギが寝ている画像は生成されないでしょう。
このように、単語としては理解できるが、その描写をAIが理解できていないので生成できないわけです
「坂本龍馬の友人が海辺で寝ている」風景を想像してください。ここであなたが想像した風景は人によって異なるはずです。なぜなら、「坂本龍馬の友人」を実際に知っている人はいないからです(多分)。
海辺に寝ている様子は、皆さんが実際に見た「海辺の風景」と「人が寝ている風景」を脳が勝手に合成していると思いますが、坂本龍馬の友人は、合成する素材が幅広すぎて全く違うものになると思います。
人によっては「おじさん」、または「子供」になるかもしれませんし、「青年」になるかもしれません。
こういうことです。
DreamBoothで欠点解消
ここで、以上の欠点を補うために考案されたのがDreamBoothです。
簡単に言うと、新たな画像をタグとともに追加でモデルに入れることです。そうすることで、元の画像生成モデルになかったタグに対応できるようになり、画像生成の幅が広がるわけです。
上記の例でたとえると、「坂本龍馬の友人の画像」を「"Friend of Ryoma Sakamoto"」のタグとともに入れると、「坂本龍馬の友人が海辺で寝ている画像」が一様に生成可能になります。
このように、もともとの画像生成能力を保ったまま、様々な文脈にあったシーンをさらに幅広く生成できるようになることで、モデルの汎用性を高めることができます。
DreamBoothの画像生成の変化の一例
今から、DreamBoothがどれほどの効力を持っているのか、論文の画像を引用して紹介いたします。
以下の画像をご覧ください。


上記の例では、左の"input images"の画像を学習データとして、新たな概念をAIに与えてあげた結果を右の複数の画像で表しています。
犬について学習したAIは、その犬の特徴をしっかりとらえて、瓜二つな犬の絵を生成しています。また、"in the Acropolis"、"in a doghouse"などプロンプト(呪文)を与えてあげることで、そのシーンにあった画像を適切に生成しています。
これが、txt2imgというもので、txt(テキスト)からimg(画像)を生成することです。
ほかにも、img2imgというものがあります。
これは、画像から画像を新たに生成するというものなのですが、正確には画像とプロンプトの2つを入力することによって、新たな画像を生成します。
DreamBoothを使えるようにする
実際にDreamBoothでファインチューニングを行うまでを紹介します。
ですが、それなりに高スペックなPCを持ってないと正直難しいです。というのも、DreamBoothは、少量の画像データから高精度の学習ができる優れものの技術ですが、マシンスペックを食うのです。
目安としては、VRAM12GB以上で、メモリが48以上だと調べた結果推測されました。
私のPCは、VRAMが8GBなので学習できませんでした...泣)。
なので、学習するまでの方法は解説しますが、学習はしません。
AUTOMATIC1111の導入
AUTOMATIC1111は、Stable Diffusionのモデルで画像生成するためのGUIアプリです。
AUTOMATIC1111は、読み込んだStable Diffusionモデルから画像を生成したり、超解像などもできるものです。
問題点としては導入が結構めんどうなところです。プログラムの知識がなければ難しいかと思います。なんせめちゃくちゃエラーがでるんでね。
このAUTOMATIC1111には、拡張機能としてDreamboothがありますので、それを使うために導入します。
AUTOMATIC1111のダウンロード
ではまず、AUTOMATIC1111をダウンロードします。
以下のコマンドでgitからダウンロードできるので行ってください。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
必要パッケージのインストール
そのあと、cdコマンドで中に入って、webui.shを起動します。
cd stable-diffusion-webui
./webui.sh
この操作により、必要なライブラリなどが自動で入ります。その後、以下のような画面になったら、赤線部のURLをブラウザに貼り付けて入りましょう。

他にも必要な操作がありますので、コマンドライン上で"ctrl + C"で接続を切って終了してください。
これで、一通り必要なライブラリやパッケージが自動で入ると思いますが、xformersだけは自分で入れなければいけないのでやっていきます。
xformersのインストール&設定
xformersのインストール方法には、以下の2通りあります。
pip install xformers
もしくは
# gitから最新のコピーを複製する git clone https://github.com/facebookresearch/xformers.git
# 中へ移動 cd xformers
# 依存関係の更新 git submodule update --init --recursive
# requirements.txtに記載されている依存関係のライブラリをインストール pip install -r requirements.txt
# 編集可能な形でインストールすることで、パッケージを常に最新の状態に維持 pip install -e .
次に、webui.shを編集します。webui.shの中にある"COMMANDLINE_ARGS="のコメントアウトを外し、以下のように書き換えます。
export COMMANDLINE_ARGS="--xformers"
これで一通り完了しました。もう一度"./webui.sh"を実行して、URLに入りましょう。
GUIが表示されれば完了です。
ここまでで起きたエラーの対処
ですが、ここまで一発で行ける方は少ないんじゃないでしょうか。なにぶん最近のものですので、日々のバージョンアップやライブラリの更新などでエラーが多数おきます。
ここまでで起きたエラーについては、私の経験では、以下の理由であることが多いと思います。
1.pipが最新ではない。
pipが最新に更新されていないと、十分なバージョンのライブラリをインストールできません。以下のコマンドで更新しましょう。
pip install --upgrade pip
2.setuptoolsが最新ではない。
setup.pyでエラーが起きている人はおそらくこれです。以下のコマンドでインストールしましょう。
pip install -U setuptools
3.Pythonのバージョンが古い or 新しい
公式がAUTOMATIC1111を動かす環境で推奨しているPythonのバージョンは3.10.9です。これよりも古すぎるか新しいとできない可能性が高いです。
pyenvやdockerなどで環境を変えましょう。
4.CUDAが入っていない
これに関しては、どっちかというと画像生成の際にエラーが起きると思うのですが、"cudnnが見つからない"や"CUDA toolkitがない"などのエラーになると思います。
これの対処法については、以下のサイトが非常に参考になりますので、以下のURLより飛んでCUDAを入れましょう。
DreamBoothの導入
AUTOMATIC1111を起動して、拡張機能からDreamBoothを探してinstallしましょう。
"Extensions" → "Available"タブ" → "Load from:"ボタン → "DreamBooth"右のinstallボタンを押してインストールする。
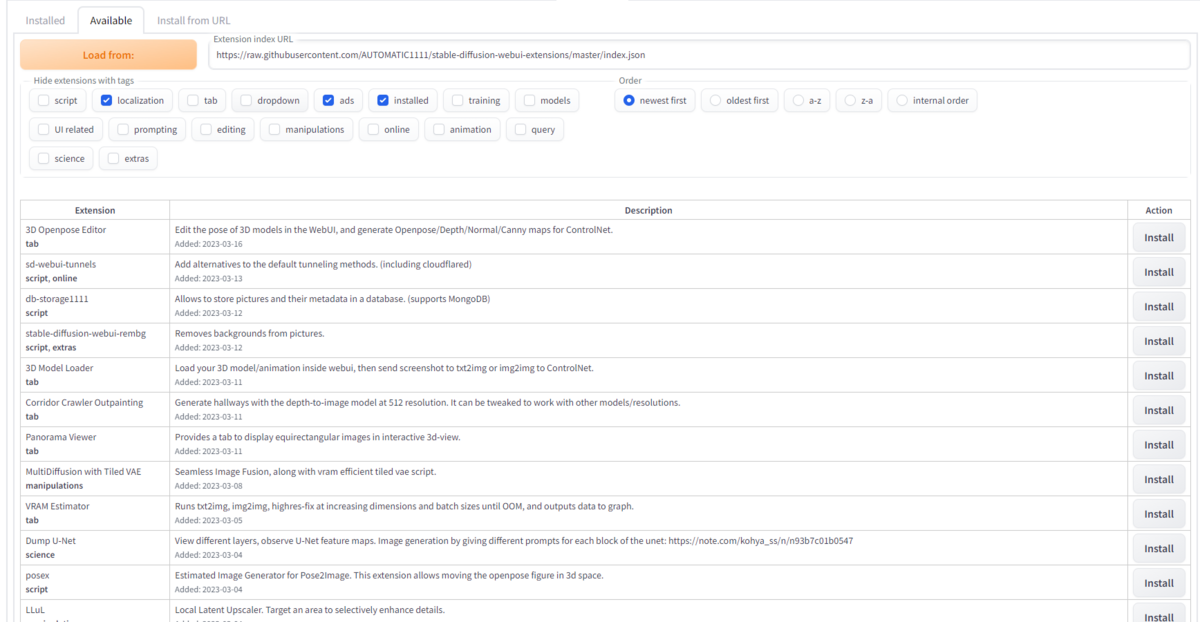
私は、すでに導入済みなのでありませんが、最後のように拡張機能のリストがずらっと並んだ中から、"sd_dreambooth_extension"という項目を探して、右のinstallボタンを押しましょう。
すると、CUI上でプログラムが動いていろいろ表示されていきます。
そして以下のような感じになれば成功です。
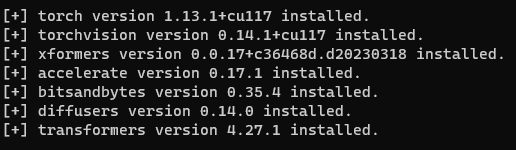
左の[ ]の中が全部" + "になっていれば正常にインストールされているということです。これが" ! "や何も書かれていない状態となると、その部分がインストールに失敗しています。
正直、初めからすべてにチェックが入っているほうが珍しいというか多分いないくらいだと思うので、落ち着いて対処しましょう。
ここまでで起きたエラーの対処
では、DreamBooth拡張機能を入れる際に起きるエラーの対処法を書いていきます。
1.Windows版Anacondaを使っている
私は、もともとwindows版anacondaで環境構築をしていたのですが、ライブラリのバージョン関係や、windowsターミナルとlinuxのCUIとのコマンドの違いなどにより、エラーが大量に出ました。
対応策としては、dreamboothの"requirements.txt"に書かれているパッケージを一つずつ手動でインストールしていく方法があります。ですが、実際にpipでインストールできないものがあり"mediapipe-silicon"や"tensorflow-macos"は失敗してしまうので、別のインストール方法を試すほかありません。
しかも、全部手動でインストールした後も[ ]が" + "にならないことが多々あります。
なので、おとなしくwindows11に更新してWSL2のubuntu20.04LTSで環境構築したほうが圧倒的に楽ですので環境を変えましょう。
2.xformersのバージョンが違う
これは、xformersの[ ]が" + "にならない場合の対処法です。
私の場合は、バージョン0.0.17で動いていますが、公式ではバージョン0.0.14が推奨されているらしいので、どうやってもxformersのところが" + "にならない方は、バージョン指定してインストールしましょう。
推奨バージョンは、
"stable-diffusion-webui\extensions\sd_dreambooth_extension\requirements.txt"
に記載されていますので、手動で入力していくか、上記のディレクトリに入って
pip install -r requirements.txt
を実行するといいでしょう。
3.CUDAが入っていない
これは、AUTOMATIC1111のエラーにも書いたことですが、AUTOMATIC1111の導入ではエラーが出ず、こっちではじめてCUDAのエラーが出ることがあります。
4.ubuntuのバージョンが正しくない
これはxformersのインストールの際に出るエラーだったと思います。私の環境では、WSL2のubuntu22.04LTSではエラーが起きて入りませんでした。
詳しく言うと、cudnnのライブラリが見つからないと言われます(入れているのに)。
海外の掲示板でも書かれていたことなのですが、ubuntu22.04LTSではバグで見つからず、いろいろ設定しないと見つけられないそうですが、ubuntu20.04なら正常に入ると書かれていて、実際に変えてみたところ驚くほどすんなり入りました。
ubuntu20.04LTS以外を使っている方は、別の方法を探すか、ubuntu20.04LTSを入れましょう。
導入できたか確認
ここまでできて、なおかつすべてのインストール要件を満たした(すべての[ ]に" + "が入っている状態)ならば、いよいよ学習開始です!
と行きたいところですが、私の環境ではできないので、導入できたかの確認までで終わります......学習したい!!!!
実際に" ./webui.sh "でGUIを立ち上げてみて、以下のようにタブに" Dreambooth "があれば成功です。

ここからは、別のサイトの方が親切にわかりやすく解説してくださっていますので以下のURLから各サイトに飛んでいろいろ学習してみてください。
Dreamboothを使ったモデルの追加学習をWindowsローカルマシンで行う方法 – AUTOMATIC1111拡張編(2023/02版) | 徒労日記
Dream Booth - としあきdiffusion Wiki*
終わりに
今回は、Dreamboothの使い方やどういうものなのかについてザックリ調べてみました。少量の画像でファインチューニングするだけでいいなんてすごいですよね。人によっては30枚とか20枚とかでも正確に特徴を捉えられたらしいので、本当にワクワクします。
ですが、初めに言いました通り、筆者はこの技術の悪用は推奨しておりません。個人的な利用の範囲だけにとどめておき、すべて自己責任にてお願いします。
時間があれば、Dreamboothの各項目についてまとめた記事や、プログラムを書いてファインチューニングをする方法も出したいと思っています。
プログラムからファインチューニングする方法だと、DeepSpeedというAUTOMATIC1111でまだ実装されていない技術を使用して、メモリ消費を減らして学習できるらしいので、やってみたいんですよね。
では、最後まで閲覧いただきありがとうございました。