こんにちは。ふらうです。
今回は、自然言語処理に革命を与えたBERTを解説していきたいと思います。
私自身、今勉強中の身であるため、解釈違いなどがあると思いますが、ご理解ください。
今回はBERTの概要とアルゴリズムの解説を行いますが、今後別記事で事前学習の実践とファインチューニングの実践を行う予定ですので、またよろしくお願いします。
BERTの概要
BERTとはBidirectional Encoder Representations from Transformersの略で、訳すると「Transformerによる双方向エンコーダ表現」です。
BERTは、2018年に発表された論文
"BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"
で世に広まることとなりました。
以下に論文のリンクを貼ります。
[1810.04805] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERTは、transformerモデルのエンコーダー部分を利用したモデルです。
transformerモデルは、Encoder-Decoderモデルで、Encoder部分で時系列データをベクトルへ変換し、Decoder部分でベクトル情報から人間にわかる出力へと変換します。
なので、BERTは人間が入力した情報を特徴量に変換し出力するので、数値情報の出力の観点から、文書分類や単語の類似度算出、感情分析などのタスクに利用されます。
逆に、Decoder部分はGPTなどの人間がわかる文章を出力するモデルに利用されます。
最近話題のOpenAIのChatGPTは、このGPTモデルのGPT-3.5をベースに作られています。これはアルゴリズムなどは公開されてないのですが、基本的にtransformerモデルを利用していると思われます。
また、最近では米国時間2023年3月14日に、OpenAIはGPT-4も公開しています。
このように、現代でも研究が加速しているモデルの基盤としてtransformerモデルがあるのです。
transformerは、双方向理解ができる点から、より深く文脈を加味できるという点も注目ポイントです。
このアルゴリズムは後程説明しますが、文章を前後両方から読んで意味を理解するとともに、今までなかった機構をモデル内に取り付けたことで、飛躍的に性能を向上させることができました。
では、これらのアルゴリズムについてひも解いていきます。
BERTの基本構造と仕組み
ここからは、詳しいBERTのアルゴリズムの解説に入ります。
できる限り専門用語などは省くように説明しますので、よろしくお願いします。
モデル構造
BERTは以下のような、たくさんの層が重なっている構造になっています。
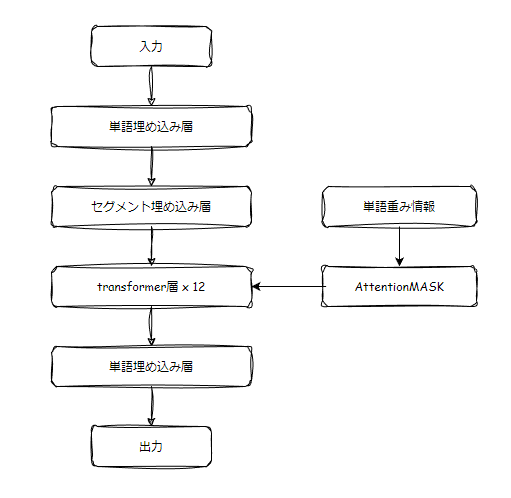
各層の役割とアルゴリズムについて解説していきます。
入力
まず、入力されるデータは文字の時系列データです。要するに文章です。
この文章は、単語に分割されて分かち書きされている必要があります。
そのあと、文章の初めに"[CLS]"というトークンを、終了地点もしくは別の文章に切り替わる部分で"[SEP]"トークンを取り付け、入力とします。
これは、文章の初めて終わりを明確に指定することで、文章を上手くAIに理解させようとしているものになります。
なので、「私は猫が好き。」という文章を入力したい場合、「[CLS], "私", "は", "猫", "が", "好き", "。", [SEP]」となります。
結論、入力は単語の列によって表現されBERTの入力となります。
単語埋め込み層
これは、一般にはembedding層と呼ばれるもので、単語それぞれに対応する単語ベクトルを割り振ります。
この単語ベクトルは、学習過程で変化していき、この単語ごとのベクトルがうまく分かれることで文章をうまく理解することが可能になります。
この単語ベクトルはランダムな初期値で振られ、学習が進むにつれて似た意味を持つ単語同士は似たベクトルになり、意味が離れた単語ほど逆向きのベクトルとなります。
BERTの特徴が深く表れている面がここにもあり、同じ単語でも文章の流れ(文脈)によって違うベクトルに直される場合があります。今までの分類モデルでは、同じ単語はすべて同一の単語ベクトルへ定義されていたのですが、BERTでは文脈を加味したベクトルへ直される構造をとっているため、文脈によってベクトルが変化します。
セグメント埋め込み層
ここでは、まず文章の連結を検知してそれぞれの文章に対応したIDを割り振ります。
BERTでは、入力の際に複数の文章を入力すると、「[CLS]私は猫が好き。[SEP]俺は犬が好き。[SEP]」のように複数の文章が連結して入力されます。これはmax_lengthなどで指定することができ、512とした場合、合計が512文字になるよう文章が連結します。
なので、どこからどこが一文なのかを理解するために、IDを割り振ります。「私は猫が好き。」には1を。「俺は犬が好き。」には2を割り振る場合は、「[CLS], 1, 1, 1, 1, 1, 1, 1(SEP), 2, 2, 2, 2, 2, 2, 2(SEP)」という風な位置セグメントIDが割り振られます。
そのあと、そのIDぶんの重みをトークンのベクトルに加算します。そうすることで、文章間の分かれ目を見分けることが可能になります。
この層があることで、文章の分かれ目を明示的に示すことで、より文脈を認識させることが可能になります。
transformer層
transformer層は、transformerモデルのEncoder部分です。
これは、過去記事で解説したものと同様の処理を行うため、以下に記事のリンクを貼っておきますので、そちらからご確認ください。
今回は、このtransformerモデルにAttentionMASKというものが追加されています。
これは何なのかというと、不必要な部分にマスクをかけて学習の際に該当箇所を読まないようにする処理です。
例えば1文章ごとに、頭から100文字をそれぞれ学習データとして読んでほしい場合に、頭から100文字に"1"を、それ以降に"0"を当てはめて、0が割り当てられた部分を読まないように処理を変更することで可能になります。
この利点としては、文章が混ざってしまっている場合やメモリの節約で読むデータを減らしたいときに有効になります。
主に大規模言語モデルでは、512もしくは768に設定されることが多いです。
出力
出力層では、学習されたベクトルが出力されます。
入力された単語列がベクトルとなって出力層から出力されます。
このベクトルを使って、文書分類や類似単語検索などを行う様々なタスクへと応用させます。
おわりに
今回、BERTについて解説しました。文書分類や様々なタスクに応用が利くほか、追加の学習(微調整)で必要となるデータが少量でいいことが魅力となり革新的なAIモデルとなりました。
しかし現在、GPT-4やBard、bingAIの登場によって、文書分類などのタスクをこなす文章生成モデルが登場してきたことで下火になってきた感じが多少ですがあります。また、langchainやLlamaIndexを使うことで単語や文章をベクトルに変換することも可能ですし、変換機としての役割も果たしてしまっています。Decoder部分でEncoderの役割まで網羅してしまうなんてすごいですわ(Encoderも使っているかも?よくわからないです)。
ですがGPT-4などは微調整がまだできませんし、できるとしてもあそこまで大規模なもモデルであれば、対話データが大量に必要になってくる可能性があります。また、利用にお金がかかる点でBERTがまだ活躍できる場は全然あります。
現在、研究でGPT-4を使っての文章分類を試験的に行っていますが、BERTをも超える場合があると感じているのも確かです。しかも分類した理由まで説明してくれるもんですから感激しました。
これからもいろんなAIが登場してくると思うので、楽しみですね。
では。
ps.最近、粉瘤らしきものができて気になってる。手術怖い。