こんにちは。ふらうです。
今回はAUTOMATIC1111上で、Stable Diffusionモデルを利用して画像生成を行うまでを解説します。
また、AUTOMATIC1111をインストールする方法は以下の記事で解説してますので、こちらもよろしくお願いします。
frqux.hatenablog.com
各拡張子のファイルの役割について 各プラットフォームで配布されているファイルには、主に以下の拡張子のものです。
.ckpt
.safetensors
.yaml
.vae.pt
まずは、これらのファイルの役割を解説します。
.ckpt この拡張子のファイルは、モデルのチェックポイントファイルです。チェックポイント(check point)の各単語の頭文字と終わりの文字をくっつけて「ckpt」です。
ckptファイルは性質上、割と危険であったりもします。悪意のあるckptファイルだった場合、復元したと同時に最悪、不正なコードが実行されてPCが汚染されたりします。
.safetensors この拡張子のファイルも、モデルのチェックポイントファイルです。
この拡張子のファイルには、モデルの構成データが記されています。json 」や「.py」で記されることがありますが、「.yaml 」で記したほうが単純で分かりやすいのだそうです。
こちらは、もし配布サイトにモデルファイルと一緒においてあれば一緒にダウンロードして、モデルファイルと同じフォルダに入れたほうがいいです。yaml ファイルがなくても使用できましたので謎です。詳しい方、コメントなどで教えてくださると幸いです。
.vae.pt この拡張子のファイルは、vaeデータです。エンコーダー のことで、画像生成に使われる用途としては、画質向上です。タセット を使って学習したほうが性能が上がるからです。
基本的にこれもモデルファイルと同時にダウンロードされることが多いです。
ある特定のモデルに特化したvaeは以下のstable diffusionのモデルファイルに入れる。
\\wsl.localhost \Ubuntu -20.04\home\[UNIX user name]\stable-diffusion-webui\models\Stable-diffusion
様々なモデルに使うことを想定したvaeは以下のVAE専用のフォルダに入れる。
\\wsl.localhost \Ubuntu -20.04\home\[UNIX user name]\stable-diffusion-webui\models\VAE
という風に保存しましょう。
prunedとfp16・fp32の違い モデルファイルには、ファイル名の中に「pruned」という名前が入っているものがあります。
しかし、「不要な部分ってどんな部分?」、「性能は本当にあまり変わらないの?」って思いますよね。そういったところまで書いているサイトが見る限りなかったので調べてみました。
tensorflowの公式リファレンスで調べてみると、以下のような記事が見つかりました。
www.tensorflow.org
簡単に言うと重要度に基づいて重みを変えていき、不要なものを取っ払う方法らしいです。
詳しく説明します。ニューラルネットワーク の中の重みを学習していく段階で、複数の重みを徐々にゼロに近づけていきます。すると、ほかのゼロに近づいていない部分の重みで出力を正そうとします。この流れで、最終時に複数の重みをゼロに限りなく近くしてから、その部分を削除することで重みデータの削減につながります。
わかりやすく具体例を挙げて説明します。まず、バナナが何か分類するために以下の三択を与えます。
もちろん正解は「果物」なので、「野菜」と「肉」の重要度は下がります。その後さらに選択肢を与えます。
木の上にできるもの
木の下にできるもの
土の中にできるもの
これは「木の上にできるもの」が正解なので、それ以外の重要度は下がります。こういった学習の過程でランダムに各選択肢の重要度をゼロに近づけていって、最終的に指標を下回った重要度の選択肢は削除される形になります。
機械学習 では、重み(例の中での重要度)一つ一つがファイルサイズを大きくする要因なので、それが削減されることでファイルサイズが小さくなります。さらに、重要度が指標を下回ったものを消すので、性能も高めたままにすることができるのです。
実際はランダムにゼロに近づけるらしいので正解の選択肢も、もしかしたらゼロに近くなってしまうかもしれません。でも学習は基本的に何千回・何万回とループさせるのが基本なので、最終的に重要であれば指標を下回る事はないといえます。多分。
なので、結果から言うと性能はprunedのほうが若干下がります。
さらにその中でもfp16とfp32の2種類がありますが、fp16が基本的に選択されています。
fp32は、単精度浮動小数 点と呼ばれているものです。これは、10^38桁の数値を有効桁数7〜9桁で表せます。精度をあまり重視しない場合に使われるみたいです。
また、fp16は半精度浮動小数 点と呼ばれているもので、これは、〜10^-8から〜65504の間で、有効桁数4桁の範囲で表現可能なものです。fp32と比べて半分ほどのメモリ量で使用されるため、更にファイルサイズが小さくなります。fp32よりも精度を重視しない深層学習などで使われるみたいです。
ちなみに、Dreamboothなどで追加学習したい方はfp16はお勧めできません。prunedモデルか、素のモデルを利用するようにしましょう。
なので最終的な結論としては、「容量を食いたくないし、少しの性能差ならどうでもいい!」という方は"prunedのfp16モデル"を、「容量は気にしてないから性能が一番いいものを使いたい!」という方は通常のprunedと書かれていない素のモデルをダウンロードしましょう。
emaとnon emaの違い これもモデルファイルの違いです。加重移動平均 のことです。加重移動平均 とは、直近のデータを重要視した平均です。加重移動平均 は70に近い値をとることになります。
なので、emaモデルは直近の性能の重みを採用しているものであると言えます。
正直、初心者目線だと違いがいまいちわからないし、ファイルサイズも一切変わらないのでどっちでもいいと思います。ただ、基本的に推論モデルにはemaを使うことになっているらしい(reddit 情報)なので、emaモデルを使うのが無難 といえます。
実際にモデルとvaeを選んで画像生成する ここまでの説明を見ればだいたい、どのファイルがどんな役割を果たすのか分かったと思います。
AUTOMATIC1111の起動 まずAUTOMATIC1111を起動させましょう。
ubuntu を起動して、stable-diffusion-webuiフォルダの中に入って以下のコマンドで起動できます。
./webui.sh すると以下の画像のような画面がブラウザを介して開かれると思います。
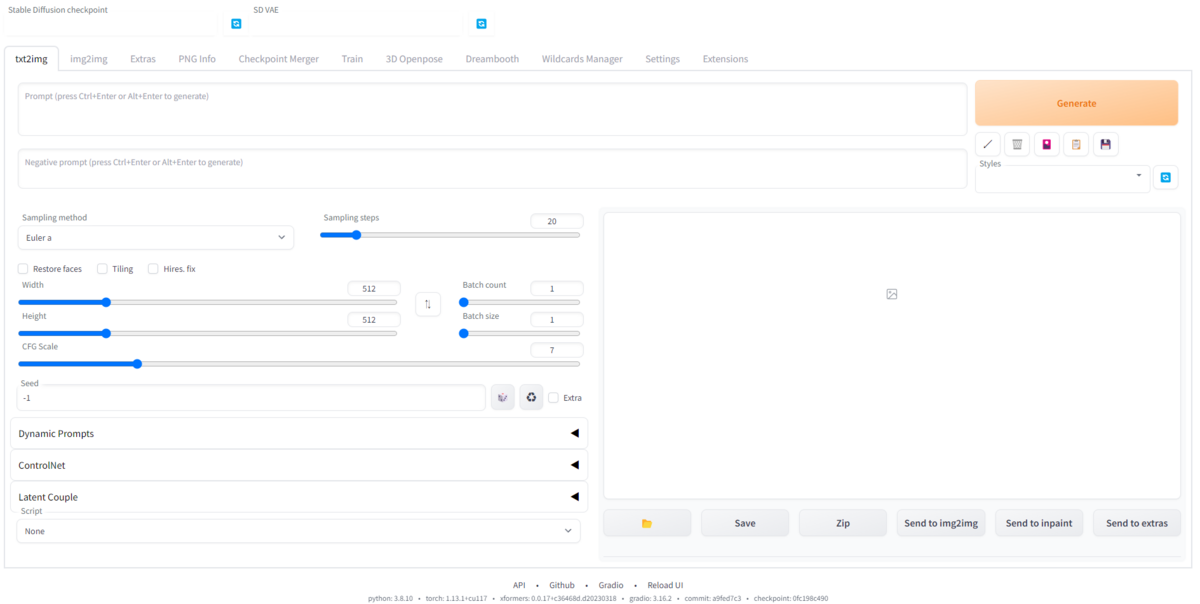
メイン画面 これで起動は完了です。
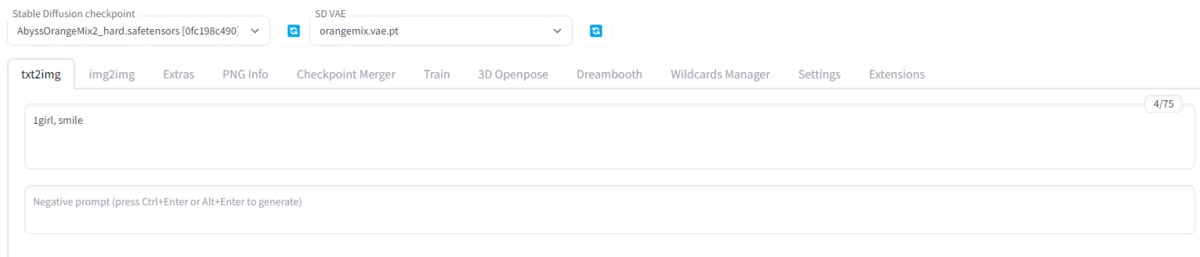
モデルファイルとvaeファイルのセット 左上の「Stable Diffusion checkpoint」にモデルファイル 。「SD VAE」にVAEを設定 しましょう。
設定するとファイル名が表示されるようになり、セット完了になります。
プロンプト(呪文)の設定 次にプロンプトを入力します。
"prompt(press Ctrl+Enter or Alt+Enter to generate)"と書かれている欄に生成したい画像の特徴を入力していきます。
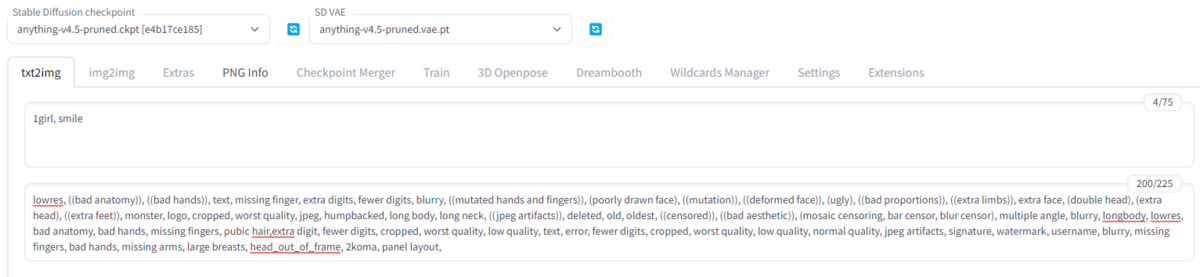
次にネガティブプロン プトを入力します。
ここでネット上からかき集めてきたネガティブプロン プトを以下に記しますので、以下の内容をコピペして貼り付けましょう。
lowres, ((bad anatomy)), ((bad hands)), text, missing finger, extra digits, fewer digits, blurry, ((mutated hands and fingers)), (poorly drawn face), ((mutation)), ((deformed face)), (ugly), ((bad proportions)), ((extra limbs)), extra face, (double head), (extra head), ((extra feet)), monster, logo, cropped, worst quality, jpeg, humpbacked, long body, long neck, ((jpeg artifacts)), deleted, old, oldest, ((censored)), ((bad aesthetic)), (mosaic censoring, bar censor, blur censor), multiple angle, blurry, longbody, lowres, bad anatomy, bad hands, missing fingers, pubic hair,extra digit, fewer digits, cropped, worst quality, low quality, text, error, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, missing fingers, bad hands, missing arms, large breasts, head_out_of_frame, 2koma, panel layout, 中身は、monster(化け物)やworst quality(最低品質)などが入ってます。
もっといい方法で、Embeddingファイルを利用する方法があるのですが、以下の記事で紹介してますので参考にしてください。
frqux.hatenablog.com
ここまで行うと以下のようになります。
必要最低限の設定をしたので、右の「Generate」ボタンを押してください。すると、画面右側に画像が生成されます。
この状態では以下のような画像が生成されました。
モデル:Anything v4.5 これで画像生成ができました。
Sampling method ... サンプラー の設定。サンプラー によって、生成される速さや品質を変えることができる。処理速度なら「Euler a」、クオリティなら「DPM++」から始まるサンプラー を選ぶとよい。
Sampling steps ... サンプリングするステップ数。数が多ければ多いほど多くのステップを踏んで画像が生成されていくのでクオリティが高くなりやすい。だがもちろんステップ数が多いほど時間がかかる。おすすめはデフォルトの「20」。
Width・Height ... 出力される画像を縦横のサイズ。少し変えるだけで生成時間が大きく変わるほか、縦横のサイズを大きくしすぎるとVRAM不足になって、CUDA out of memoryのエラーが出て生成できない場合がある。おすすめは、縦横合わせて1000近くなるよう数値を調整するといいでしょう。
Batch count ... 画像が生成される回数。
Batch size ... 一度に生成される画像の数。
CFG Scale ... 生成画像の内容をAIの感覚に任せるか、プロンプトを重視するかの割合。数値を小さくすればするほどプロンプトとは違った絵になりやすいが、自然な仕上がりになる。逆に数値を大きくすればするほど、プロンプトの内容に近い内容の絵になるが、無理やり近づけていくため絵が崩れてしまいやすい。おすすめは4~8の間。また、LoRAやLyCORISを使っている場合、おすすめのCFG Scaleがダウンロード元のページに記載されている場合があるのでそれを参考にするといいです。
Seed ... 初期値(シード値)。これを指定すると、同じシーンを生成できるようになる。例えば、シード値を「1000」に設定して画像生成したときに自分好みの絵が生成されたとします。そして、また別の機会に同じ絵を生成したい場合、また同じプロンプトを入力して、シード値に「1000」と入れて画像生成するとまったく同じ画像が生成されるようになる。初期値は「-1」となってますが、これはシード値を完全ランダムにするという意味です。特別なことがない限り「-1」のままのほうがいいです。
終わりに 今回は、AUTOMATIC1111での画像生成を行う方法を解説しました。
また、このプロンプトから新しい絵を生成することをtxt2img(text to image : テキストから画像に)というものになります。
これのほかにも、img2img(image to image : 画像から画像に)というものもあります。
また、AUTOMATIC1111には、txt2imgで生成した画像をimg2imgにそのまま直接送ることができる("Send to img2img"を押す)ので、使用用途は結構あります。
また時間があれば解説したいと思っています。
それでは、最後まで閲覧いただきありがとうございました!